
Hongxin Yan, University of Eastern Finland
Fuhua Lin, Athabasca University, Canada
Kinshuk, University of North Texas, USA
Online higher education provides exceptional flexibility in learning but demands high self-regulated learning skills. The deficiency of self-regulated learning skills in many students highlights the need for support. This study introduces a confidence-based adaptive practicing system as an intelligent assessment and tutoring solution to enhance self-regulated learning in STEM disciplines. Unlike conventional intelligent tutoring systems that depend entirely on machine control, confidence-based adaptive practicing integrates learner confidence and control options into the AI-based adaptive mechanism to improve learning autonomy and model efficiency, establishing an AI-learner shared control approach. Based on Vygotsky’s zone of proximal development (ZPD) concept, an innovative knowledge tracing framework and model called ZPD-KT was designed and implemented in the confidence-based adaptive practicing system. To evaluate the effectiveness of the ZPD-KT model, a simulation of confidence-based adaptive practicing was conducted. Findings showed that ZPD-KT significantly improves the accuracy of knowledge tracing compared to the standard Bayesian Knowledge Tracing model. Also, interviews with experts in the field underlined the potential of the confidence-based adaptive practicing system in facilitating self-regulated learning and the interpretability of the ZPD-KT model. This study also sheds light on a new way of keeping humans apprised of adaptive learning implementation.
Keywords: adaptive practicing, confidence-based assessment, knowledge tracing, question sequencing, self-regulated learning, wheel-spinning
L’enseignement supérieur en ligne offre une flexibilité exceptionnelle dans l’apprentissage, mais il exige des compétences élevées en termes d’apprentissage autorégulé. Le manque de compétences d’apprentissage autorégulé chez de nombreuses personnes étudiantes met en évidence la nécessité du soutien. Cette étude présente un système de pratique adaptative basé sur la confiance en tant que solution intelligente d’évaluation et de tutorat pour améliorer l’apprentissage autorégulée dans les disciplines STIM. Contrairement aux systèmes de tutorat intelligents conventionnels qui dépendent entièrement du contrôle de la machine, la pratique adaptative basée sur la confiance intègre la confiance de la personne apprenante et les options de contrôle dans le mécanisme adaptatif basé sur l’intelligence artificielle (IA) pour améliorer l’autonomie d’apprentissage et l’efficacité du modèle, établissant ainsi une approche de contrôle partagé entre l’IA et la personne apprenante. Basés sur le concept de zone de développement proximal de Vygotsky (ZPD), un cadre et un modèle innovant de traçage des connaissances appelé ZPD-KT ont été conçus et mis en œuvre dans le système de pratique adaptative basé sur la confiance. Pour évaluer l’efficacité du modèle ZPD-KT, une simulation de pratique adaptative basée sur la confiance a été effectuée. Les résultats ont démontré que le modèle ZPD-KT a considérablement amélioré la précision de la traçabilité des connaissances par rapport au modèle traditionnel de traçage des connaissances bayésiennes. De plus, les entrevues avec des experts dans le domaine ont souligné le potentiel du système de pratique adaptative pour faciliter l’apprentissage autorégulé et l’interprétabilité du modèle ZPD-KT. Cette étude a également mis en lumière une nouvelle façon de tenir les humains informés de la mise en œuvre de l’apprentissage adaptatif.
Mots-clés : apprentissage autorégulé, évaluation basée sur la confiance, pratique adaptative, rouet, séquence de questions, traçage des connaissances
Online education has become an important educational paradigm in the field of higher education. Self-paced online learning provides increased flexibility because learners can study anywhere, anytime, and at their own pace. Yet, self-paced online learning faces inherent challenges due to reduced synchronous interaction when learners study independently and asynchronously (Yan et al., 2020). Disciplines such as science, technology, engineering, and mathematics (STEM) demand high self-regulated learning (SRL) skills so that learners are able to self-monitor their learning progress, evaluate their knowledge proficiency, identify learning gaps, regulate learning efforts, and seek targeted support (Nuryadin et al., 2024; Schunk & DiBenedetto, 2020).
Previous research has identified a significant positive relationship between SRL strategies and online academic success (Broadbent & Poon, 2015; Nuryadin et al., 2024; Wong et al., 2019). Self-regulated learning skills become even more critical for self-paced online learning, which requires high levels of learner autonomy and has low levels of teacher presence (Lehmann et al., 2014). However, not every learner has adequate SRL skills. Learners are generally inaccurate when monitoring their learning without additional instruction (Viberg et al., 2020). In higher education, researchers have found that instructors tend to focus on course content, providing limited opportunities for scaffolding SRL (Broadbent, 2017; Jansen et al., 2019; Zimmerman, 2020). Hence, it is imperative to provide learners with a means to facilitate their SRL in self-paced online STEM higher education. Yan et al. (2022) argued that adaptive practicing could be an effective tool to meet this need. As a type of formative assessment, adaptive practicing selects exercise questions based on individuals’ knowledge states. Hence, it can assess learners’ knowledge levels, identify learning weaknesses, and provide instructive feedback and remedial materials for learning.
Adaptive practicing can use computed algorithms (Manouselis et al., 2011) to realize two core functions: knowledge tracing and question sequencing. Knowledge tracing estimates and tracks learners’ knowledge proficiency based on their responses to questions. Question sequencing decides the optimal knowledge component and the exercise to practice with each time to obtain the maximum learning gain.
One limitation of previous knowledge tracing models is that they mainly rely on the answer correctness collected during the assessment (Clement et al., 2015; Pelánek, 2017). However, if certain question types such as multiple-choice are used for assessment, it is hard to discern learners who guess correctly from those who actually know the answer (Novacek, 2013). As Clement et al. (2015) pointed out, answer correctness alone may not tell whether an exercise is effective, but with certain side information, it could. Regarding side information, Holstein et al. (2020) stated that humans may have relevant information to which adaptive learning systems are likely blind. Thus, these researchers have posited that considering learners’ subjective feelings of knowledge in adaptive learning systems can more efficiently determine whether their answers reflect actual knowledge levels. For example, Novacek (2013) suggested a confidence-based assessment in which learners select the answers they believe are correct and indicate their confidence in their selections.
Another limitation of previous adaptive learning systems is that instructional sequencing usually assumes exclusive machine control but seldom considers learner control. In the context of adaptive practicing, learners usually do not have any control over which knowledge component or question they should practice with next time. Learner control is related to the earlier conceptual development of self-directed learning in distance education, stressing learning autonomy and personal responsibility for the learning process (Sorgenfrei & Smolnik, 2016). According to self-determination theory (Deci et al., 1991), learner control can enhance learning motivation by strengthening the human need for autonomy—the desire to self-initiate, self-control one’s behaviour, control activities, and freely pursue one’s decisions. Research has demonstrated the importance of learners’ perceived autonomy to their motivation and academic performance (Hsu et al., 2019; Luo et al., 2021; Sorgenfrei & Smolnik, 2016).
Thus, considering learner inputs on knowledge judgement and question sequencing in the adaptive practicing model could increase model effectiveness and promote learning autonomy and engagement. Despite these potential advantages, few studies have explored how these learner inputs are factored into the AI agent’s decision-making. To the best of our knowledge, studies have not sufficiently investigated how learner control could be considered in an adaptive practicing model design. As noted by Doroudi et al. (2019) in a review paper, AI agents could consider learner judgements and control during decision-making, but such a form of shared control has not been investigated in the context of instructional sequencing because it is challenging to address the subjectivity of learner judgement and control. To fill this research gap, our study investigated how to incorporate learner confidence in the adaptive practicing mechanism to design an AI-learner shared control model. Through simulation, significant improvement was found in the effectiveness of such an AI-learner shared control model compared to the standard Bayesian Knowledge Tracing (BKT) model ( Corbett & Anderson, 1994).
This paper begins by reviewing previous work related to human-AI collaboration approaches and confidence-based assessment. Then we discuss how we designed a confidence-based adaptive practicing system and a ZPD-based knowledge tracing framework and model which were built in response to the research gaps identified by our literature review. We then present the findings of the evaluation of our model which was conducted through a simulation exploring the effectiveness of the model. Finally, the advantages and limitations of the model design are discussed.
First, we reviewed what has been done regarding human-AI collaboration approaches designed for adaptive learning. Then, past studies investigating how learners’ confidence is incorporated into assessment were examined.
Human-AI collaboration stresses that humans and AI are partners in achieving the overall goal, and each party contributes according to its strengths and weaknesses (Brusilovsky, 2024). The general ideas of learner control have been extensively explored in the educational field and have formed one of the foundations of SRL (Bjork et al., 2013). In the context of online learning system design, learner control refers to certain learning process features, such as control over the path, sequence, flow, and so forth (Sorgenfrei & Smolnik, 2016). Sorgenfrei and Smolnik’s analysis demonstrated that learner control over variables such as time, pace, navigation, and design is associated with improved learning outcomes.
Some studies have considered how to keep humans in the loop of AI-based adaptive learning. Brusilovsky (2024) summarized four approaches of AI-learner shared control for adaptive content selection. One approach is through the editable learner model (Weber & Brusilovsky, 2001). In Weber and Brusilovsky’s ELM-ART system, the AI determines the state of learner knowledge and displays it to the learner, while the learner has a chance to correct obvious errors. The second approach is called ranking-based human-AI collaboration (Rahdari et al., 2022), whereby AI does the work of careful selection and ranking, but the learner has the final say in selecting the most relevant content item. A third approach is adaptive navigation support (Brusilovsky, 2007) where AI works in the background to decide the best links to appropriate content, but AI advice is provided in a less direct form, and the final control is in learners’ hands. The fourth approach is that learner control is enabled during the decision-making process. For example, the system can allow the user to choose one of the available content selection algorithms (Ekstrand, 2015) or let the learner control some parameters of the recommendation process (Papoušek & Pelánek, 2017).
These approaches show some possibilities of how AI-learner shared control can be realized in adaptive learning. However, as Brusilovsky (2024) pointed out, content selection in the first three approaches is mainly done by AI agents alone, while learners are only involved at the beginning for learner model adjustment or at the end for selecting content from what is recommended by AI agents. The fourth approach requires extensive knowledge of learners in computing algorithms and adds extraneous cognitive load for learning. The limitations of previous approaches call for a more straightforward and effective AI-learner shared control model for adaptive practicing.
Multiple-choice questions remain prevalent in traditional assessments, but their reliance on binary scoring (correct/incorrect) fails to distinguish between mastered knowledge and guesswork, a limitation widely acknowledged in current pedagogical research (Preheim et al., 2023). To address this, confidence-based assessment techniques combine the answer selection with learners’ perceived certainty levels (e.g., not sure, partly sure, and sure), enabling a nuanced evaluation of knowledge mastery (Gardner-Medwin & Curtin, 2007; Remesal et al., 2023). For instance, Smrkolj et al. (2022) demonstrated that this approach improves the reliability of assessments by penalizing confidence errors and rewarding accurate self-awareness. Inspired by this confidence-based assessment technique, we proposed integrating learners’ confidence in the adaptive practicing model to improve the knowledge tracing efficiency.
To design an AI-learner shared control model, we first determined what learner inputs should be considered in the adaptive practicing model. We then describe the theories that supported our model design.
The idea of increasing interaction between humans and machine-learning algorithms is to make machine learning more accurate or to obtain the desired accuracy faster through learning with humans (Mosqueira-Rey et al., 2023). Inspired by confidence-based assessment techniques, we realized that answer responses combined with learners’ perception of their knowledge levels (e.g., confidence or difficulty rating) could potentially make knowledge tracing more efficient. For example, if learners skip a question and indicate it is too easy, or if a learner answers a question correctly and indicates full confidence, this learner likely has mastered the knowledge. The integration of such learner inputs could be an algorithmic advantage compared to the traditional knowledge tracing models, such as the BKT model (Corbett & Anderson, 1994), which typically needs many questions to train the model because of the parameters of guessing and slipping (careless mistakes) considerations. Therefore, we included confidence rating and question skipping as learner inputs in the adaptive practicing model.
After learners selected an answer to a multiple-choice question, they could indicate their confidence level on a scale ranging from no confidence to full confidence, with intermediate levels of low, moderate, and high confidence.
Our model gave learners the option to skip a question if they felt it was too easy or too hard. Learners’ question-skipping choice could override the system’s decision on question selection to avoid boredom or frustration. Also, time would be saved by skipping ineffective exercises. We argue that question-skipping is also based on learner confidence in the knowledge tested by the question.
The design of our adaptive practicing model was based on the following learning theories.
Knowledge space theory (Doignon & Falmagne, 1999) is a theoretical framework which proposes that every knowledge domain can be represented in terms of a set of knowledge components (KCs). Knowledge states represent the subset of KCs a learner has mastered or learned. Each KC is assessed by a set of questions. The KCs in a knowledge domain usually are interrelated or have prerequisite relationships. Our study treated course learning outcomes as the KCs. So, the adaptive practicing model considered the prerequisite relationships among learning outcomes when selecting the optimal questions for practicing.
The concept of zone of proximal development (ZPD) by Lev Vygotsky refers to a zone where a learner can complete tasks with assistance but not independently (Vygotsky, 1978). According to Vygotsky, concrete growth can only occur in the ZPD, and learning is most effective when timely support is provided. Traditional self-assessment usually contains a set of exercises without any adaptive mechanism. With such a one-size-fits-all assessment approach, some learners may feel under-challenged or bored, while others may feel over-challenged or frustrated. According to Vygotsky’s theory, this problem stems from the fact that each learner has a different ZPD at any given time (Vainas et al., 2019). The adaptive practicing model in this study attempted to mitigate this problem by tracking learners’ ZPD and keep them practicing in their ZPD. As a well-known and vastly researched concept in educational psychology, ZPD has laid the foundation for personalized learning, and some ZPD-based learning tools have been developed to sequence instructional content (Vainas et al., 2019).
Dynamic difficulty adjustment is a technique often used in video games to automatically adjust the game’s difficulty level in real time based on the player’s ability (Zohaib, 2018). In the field of education, this technique can be borrowed to adjust the difficulty of learning materials based on learners’ skill levels to keep them engaged. This technique can be instrumental in online environments where it is difficult to provide personalized feedback and support to individual learners. Inspired by this technique, adaptive practicing can be realized through different adaptive methods such as modifying the difficulty level of the exercises, changing the sequence of the questions, or adjusting the pace of the practice.
This study investigated a confidence-based adaptive practicing (CAP) system and a ZPD Knowledge Tracing (ZPD-KT) model design. Inspired by the Intelligent Tutoring System’s four-component structure (Nkambou et al., 2010), a six-module architecture for CAP design was developed (Figure 1). The six modules included the user interface, domain model, knowledge tracing, question sequencing, wheel-spinning detection, and system self-learning.
Figure 1
The Architecture of the Confidence-Based Adaptive Practicing System
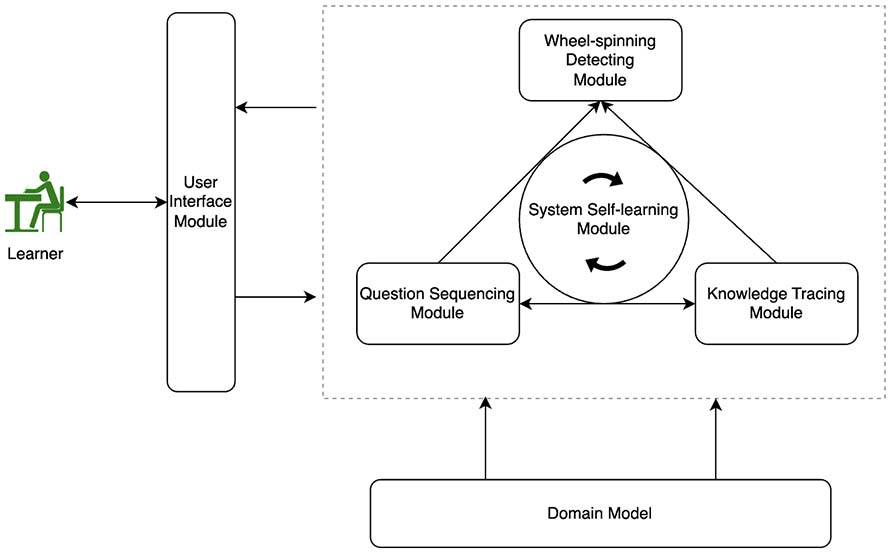
The user interface of CAP consists of essential components such as question body, options, feedback, and buttons for navigation and responding (Figure 2). Unlike conventional practicing systems, the CAP interface includes two unique components: (a) a question skip option, along with answer options whereby if a question is too hard or too easy, a learner could choose to skip it, and (b) a learner confidence rating, which allows learners to select their confidence level in the answer. After selecting an answer, learners are asked to rate their confidence using a Likert scale (1 = no confidence to 5 = full confidence).
Figure 2
Example of the Learner Interface of the Confidence-Based Adaptive Practicing System

As illustrated in Figure 1, the CAP system was built on the domain model which describes four types of information: (a) the KCs covered by the practicing, (b) the knowledge learning paths from the initial state to the final state (Figure 3), (c) the dependencies among those KCs, and (d) the exercises (including question item, options, correct answer, and feedback) corresponding to each KC. In higher education, learning outcomes are generally the competencies that learners should master, typically expressed in Bloom’s taxonomy. For the purposes of this study, learning outcomes were regarded as KCs.
The knowledge tracing module detects a learner’s knowledge state and tracks their changes during practicing. Relative to the ZPD, four cognitive statuses on a KC were defined in this study:
Wheel-spinning is a learning phenomenon analogic to a car stuck in snow or mud—the wheels will spin without getting anywhere despite devoting effort to moving (Beck & Gong, 2013).
Figure 3 shows one example of a learner’s knowledge states at a given time during practice for learning a topic. There are nine learning outcomes (LOs) in this topic: A, B, C, D, E, F, G, H, and I, each mapping to an exercise set (i.e., exercises a, b, c, d, e, f, g, h, and i). Some prerequisite relationships exit. For example, LO-B is a prerequisite for LO-E, which is a prerequisite for LO-F and LO-G.
In Figure 3, the KCs in green (A, B, C, D, and E) are mastered; KCs in yellow (G and H) are in-learning; the KC in grey (I) is unlearnable; and the KC in red (F) indicates wheel-spinning.
Figure 3
An Example of a Learner’s Knowledge States
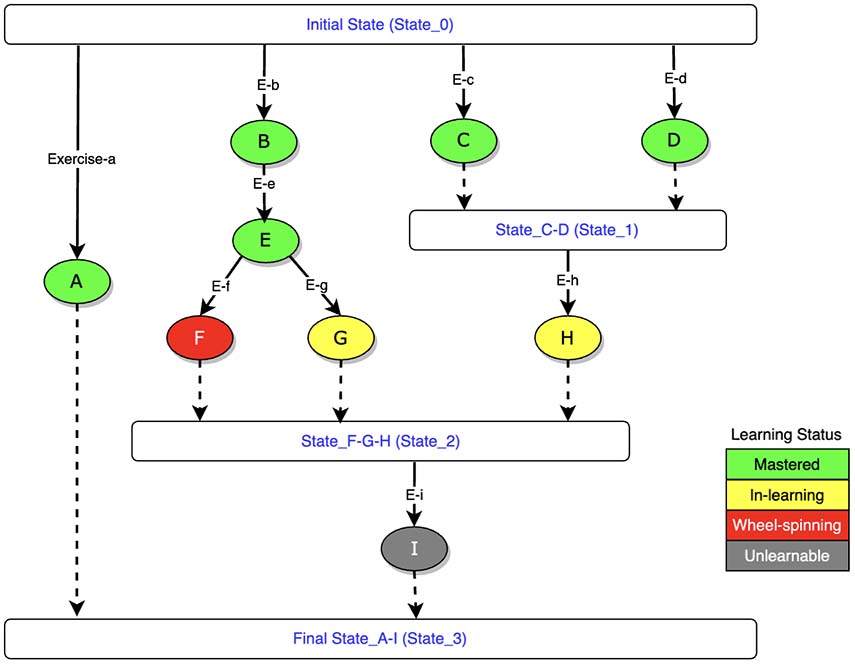
Note. Letters A through I in the figure indicate learning outcomes for this topic. Letters E-a through E-i indicate the sets of exercises that map to the respective learning outcomes.
Learners’ ZPD usually move to higher levels as they learn or practice. Figure 4 shows an example of how a learner’s ZPD moved from one level to the next, demonstrating an increase in ability. Since learning is a dynamic process, the knowledge tracing module needed to track learners’ ZPD based on their responses in order to present optimal questions for maximum practice effectiveness. That is why we chose a ZPD-KT framework and model.
Figure 4
Example of a Learner’s Changing Zones of Proximal Development as Determined by Practice Iteration
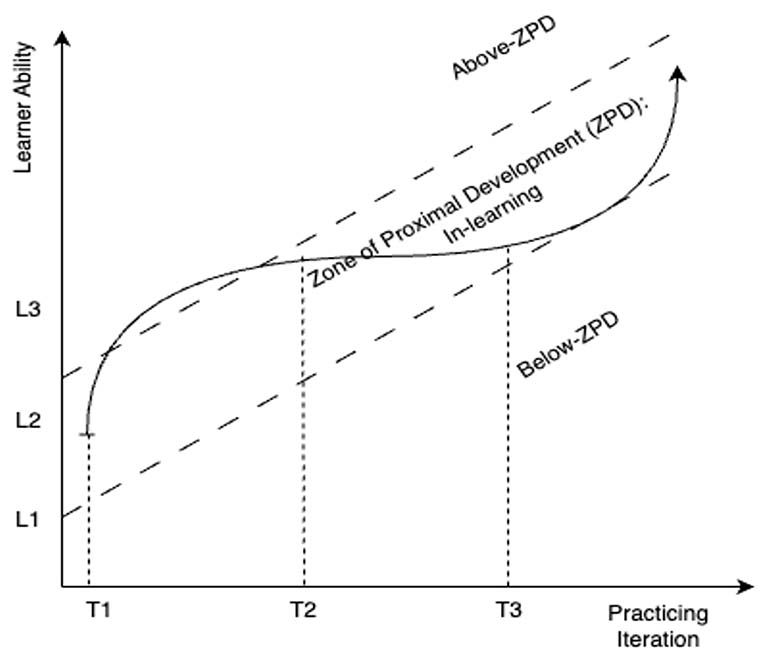
Note. L1 is Level-1; L2 is Level-2; L3 is Level-3; T1 is Time-1, T2 is Time-2; T3 is Time-3.
To use the ZPD concept for knowledge tracing purposes, nine ZPD levels corresponding to learners’ answer correctness and confidence rating were defined. These nine ZPD levels include: above, ceiling, upper, mid-upper, mid, mid-lower, lower, flooring, and below. Each ZPD level is associated with a range of mastery values. Table 1 depicts the mapping relationships between learner responses and the ZPD levels. For example, if the answer was correct and the confidence was rated high, the learner’s ZPD level would fall under ceiling and the mastery value would be in the high range [0.80-0.95]. It is important to note that the ZPD level determined by learners’ responses and confidence rating comes with some subjectivity due to reliance on learners’ reported perceptions rather than objective measures.
Table 1
Learner ZPD Categorized by Correct Answers, Confidence Rating, and Mastery
| Zone | Answer correctness | Confidence rating | Mastery range | Midpoint mastery |
| Above ZPD1 | True | Full | 0.95–1.00 | 0.975 |
| Ceiling ZPD | True | High | 0.80–0.94 | 0.875 |
| Upper ZPD | True | Moderate | 0.65–0.79 | 0.725 |
| Mid-upper ZPD | True | Low | 0.55–0.64 | 0.600 |
| Mid ZPD | True/False | No | 0.45–0.54 | 0.500 |
| Mid-lower ZPD | False | Low | 0.35–0.44 | 0.400 |
| Lower ZPD | False | Moderate | 0.20–0.34 | 0.275 |
| Floor ZPD | False | High | 0.05–0.19 | 0.125 |
| Below ZPD2 | False | Full | 0.00–0.04 | 0.025 |
Note. ZPD = zone of proximal development. 1If a question was skipped because it was too easy or mastered, the question also fell into the category of above ZPD. 2If a question was skipped because it was too hard or the learner got stuck, the question also fell into the category of below ZPD.
Based on the ZPD-KT framework, a ZPD-based knowledge tracing algorithm was created. The algorithm first examines a learner’s response to a question (answer correctness and confidence rating), and then determines the ZPD level (Table 1). The midpoint of the mastery range of that ZPD level is then used as the newly observed mastery value (denoted in Equation 1 as masteryZPD). Because of the subjectivity of the confidence rating, we decided it would be more reliable to consider the historical trend of the mastery values. Therefore, the current estimated mastery value is calculated as shown in Equation 1: the average of the previously predicted mastery value and the current observed mastery value. Then, since the practicing system provides learners with feedback or remedial materials, a learner’s mastery value is predicted to increase by a learning rate (LR), as formulated in Equation 2.
| masteryEstimated[t] = (masteryPredicted[t-1] + masteryZPD[t]) / 2 | (1) |
| masteryPredicted[t] = masteryEstimated[t] + (1 - masteryEstimated[t]) x LR | (2) |
The ZPD-KT model is more transparent and interpretable to educators than some machine learning-based knowledge tracing models (e.g., BKT). Therefore, there would be a higher likelihood of it being adopted in a real-world teaching context.
The wheel-spinning detecting module was designed to detect a learning situation where learners struggled unproductively with a KC. When feedback and remedial materials provided in the adaptive practicing could not help learners move forward, this module would alert the learners of wheel-spinning and suggest they ask for help from other sources, such as academic experts. Wheel-spinning happens when a learner keeps spending time on an unlearnable KC. Given that prerequisite relationships among KCs exist, a KC may be unlearnable because its prerequisite KCs have not yet been mastered. In such cases, the learner should be directed to the prerequisite KCs for practicing first. A learner is wheel-spinning on a KC if the following two conditions are met: (a) a KC is detected unlearnable; and, (b) all its prerequisite KCs have been mastered.
The question sequencing module provides individual learners with the optimal question sequence to obtain the maximum learning gain at each practice opportunity. The optimal question presented to a learner is based on the learner’s knowledge state predicted in the knowledge tracing module. In the CAP system, question sequencing consists of two steps: (a) select the optimal KC from all KCs that are not mastered yet for practicing, and (b) select the optimal question from a question pool corresponding to the KC. The optimal KC selection is determined by three factors: (a) prerequisite relationships among KCs (the prerequisite KC should be practiced first); (b) the mastery level of each KC (the KC with a mastery level closer to upper ZPD should be practiced first in the CAP system); and (c) the Bloom’s taxonomy level of each KC (the KC with lower level should be practiced first). Equation 3 formulates the optimal score calculation for KCs by summing the score of each factor with a certain weight, expressed in the equations as kcScore. After a KC is selected, a question is chosen from a question pool corresponding to the selected KC by checking their difficulties against the KC mastery level and their practice history (as shown in Equation 4). The weights were initially set based on experts’ experience.
| kcScore = w1 x prerequisteScore + w2 x masteryLevelScore + w3 x BloomScore | (3) |
| questionScore = w4 x difficultyMatchScore + w5 x practiceHistoryScore | (4) |
Learning is a complex process. In the environment of adaptive practicing, there are many additional uncertainties. First, the learner confidence rating is somewhat subjective. For example, learners may be overconfident or underconfident in their knowledge level. Second, the prerequisite relationships among KCs could be hard or soft and sometimes challenging to quantify. In addition, the effectiveness of exercise questions for a particular KC can vary widely. Therefore, the cognitive status deduced by learners’ responses reflects a likelihood rather than certainty. For example, if learners answer a question correctly and indicate full confidence, it is likely that learners have mastered the knowledge, but it is still possible that this is not the case. To avert the subjectivity of learner confidence and improve the accuracy of knowledge tracing in the CAP, a system self-learning module was designed. This module aimed to optimize the LR (as shown in Equation 2) by analyzing learning data continuously collected from the system. The expectation-maximization technique was used in the system self-learning module to find the maximum likelihood of the parameter, in this case, the LR.
It is crucial to evaluate the CAP system and the ZPD-KT model design for their effectiveness in tracing learners’ knowledge, selecting optimal exercise questions, and detecting wheel-spinning. Two evaluation phases were conducted: (a) interviews with experts to gain insights into the strengths and weaknesses of the model design, and (b) simulation of the model to test its effectiveness.
In the first phase, feedback was gathered by interviewing four experts: three in the field of computing for education and one in physics. These experts work at an online university and teach self-paced courses in STEM disciplines. During the interview, we explained the purpose of this research project, demonstrated the CAP system, and explained the ZPD-KT model. All interviewees indicated they had already realized the SRL-related challenges in self-paced online education, and agreed that: (a) embedding such adaptive practicing activities in courses could be an effective solution to address this challenge for STEM disciplines; (b) the ZPD-based knowledge tracing framework and algorithm are easy to understand and make sense; and (c) incorporating learner confidence and learner control could help improve learner engagement and learning autonomy. The experts also offered some suggestions for design improvement. For example, some wondered whether the large language model AI technology could help instructors create exercise questions to reduce their workload, whether different question difficulty levels should be considered, whether the learning rates should be personalized for individual learners, and so forth. Based on this feedback, the model design was refined.
In the second phase, a simulation of the CAP system and the ZPD-KT model was conducted. Running a simulation allows for thorough testing of its functionality before implementation. Simulating various scenarios allows potential flaws and issues to be identified and addressed in the design stage. By testing the system with different data inputs and user behaviours, it is possible to optimize the algorithms to make the design more effective, accurate, and robust.
The simulation was created in JavaScript for a web application. We simulated a computer science course with five learning outcomes (KCs) at different Bloom’s taxonomy levels (i.e., remember, understand, apply, analyze, evaluate, or create). Certain prerequisite relationships were set up for these learning outcomes. Each learning outcome mapped to a pool of exercise questions with different difficulty levels. A total of 8,000 learners were simulated. The main goal of the simulation was to find out how well the ZPD-KT predicted the mastery value at each practicing opportunity, or how much the prediction error would be. Therefore, these learners were randomly assigned an initial estimated mastery value for each learning outcome following a normal distribution. A learning rate was specified for predicting the new mastery value. Also, these learners were randomly assigned an initial actual mastery value for each learning outcome. A random value between 0.1 and 0.3 was drawn as the actual learning increment at each practice opportunity. The ZPD-KT model needed to track the changing knowledge levels of all learners who had different initial actual mastery values and learning increments. To do this, we also simulated the standard Bayesian Knowledge Tracing (stdBKT) model as the baseline for comparison.
First, the simulation helped refine the ZPD-based knowledge tracing algorithm. Also, it showed that the ZPD-KT model has significantly higher prediction accuracy than the stdBKT model.
By experimenting through simulation, we discovered that the prediction accuracy could be improved significantly if the learning rate was adjusted for each practicing opportunity based on their mastery values (Equation 5).
| LR = baseLR x masteryZPD[t] x [1 + (masteryZPD[t] – masteryPredicted[t-1])] | (5) |
By running the system self-learning module, we identified that the optimal base learning rate (baseLR) is 0.517.
The simulated practicing data for both ZPD-KT and stdBKT models were compared for prediction accuracy. Figure 5 shows each model’s average prediction deviation for each learning outcome. Figure 6 shows an example of the knowledge tracing progression on a learning outcome for a student comparing the two models.
The average prediction deviation is calculated as shown in Equation 6:
ΣTt=1 (Pt – At) T | (6) |
t = practice time
T = the total number of practices
Pt = the predicted mastery value at time t
At = the actual mastery value at time t
Figure 5
Prediction Deviation Comparison Between the Two Research Models
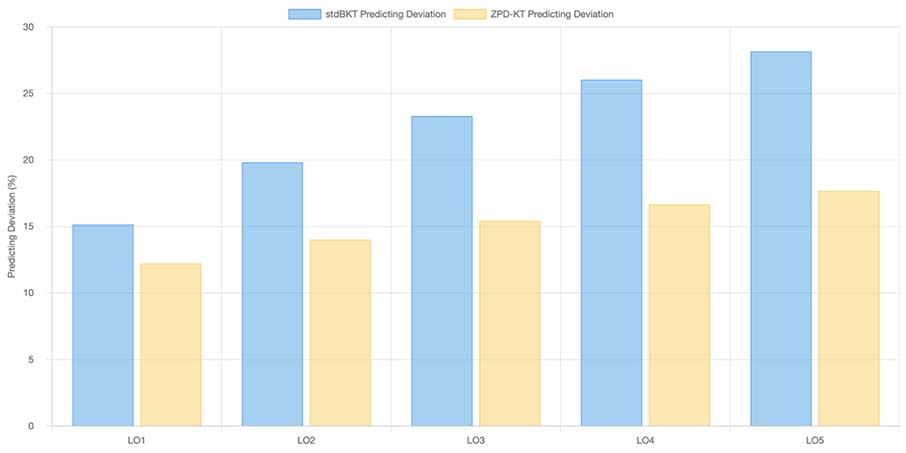
Note. stdBKT = standard Bayesian Knowledge Tracing; ZPD-KT = zone of proximal development knowledge tracing; LO = learning outcome.
Figure 6
An Example of Knowledge Tracing Progression of ZPD-KT vs. stdBKT
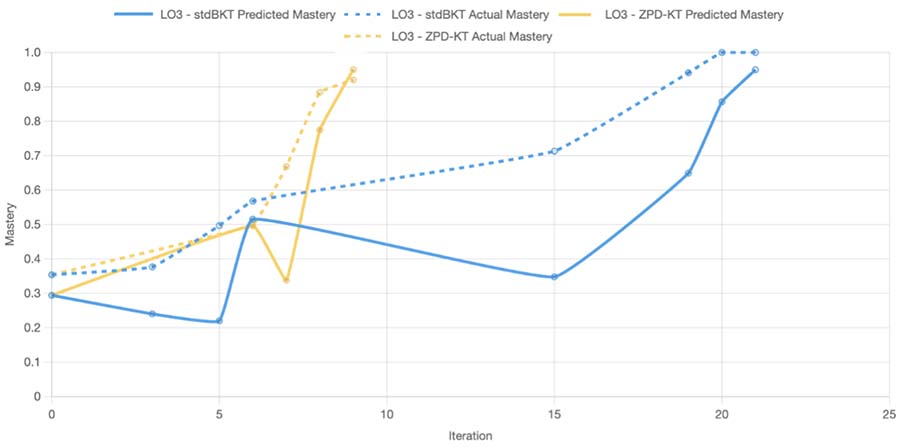
Note. stdBKT = standard Bayesian Knowledge Tracing; ZPD-KT = zone of proximal development knowledge tracing; LO = learning outcome.
Table 2 shows two comparison metrics for all learning outcomes and all students: (a) the average prediction deviation from the actual mastery value and (b) the accuracy of predicted mastered status.
Table 2
Overall Comparison Between ZPD-KT and stdBKT Model
| Metric | stdBKT | ZPD-KT | stdBKT vs. ZPD-KT t | p |
| Average prediction deviation | 0.174999 | 0.116735 | 26.05 | <.0001 |
| Accuracy of predicted mastered | 82.83% | 88.29% | -24.41 | <.0001 |
Note. stdBKT = standard Bayesian Knowledge Tracing; ZPD-KT = zone of proximal development knowledge tracing.
With a learner sample size of 8,000 and total trials of around 20,000, the statistical comparison between stdBKT and ZPD-KT reveals significant differences in both metrics. For average prediction deviation, the t-statistic is 26.05, indicating a highly significant difference favouring ZPD-KT’s lower deviation. The accuracy of predicted mastered again shows a significant difference in favour of ZPD-KT’s higher accuracy. These results strongly suggest that ZPD-KT outperforms stdBKT in both prediction accuracy and mastery identification, with the large sample size providing robust statistical evidence for these conclusions.
Traditionally, higher education courses mainly focus on instructional content. As more educators realize that SRL can be a critical factor for online learning success, they are using formative assessment to permit learners to self-check their knowledge proficiencies and weaknesses. Nevertheless, Ebbinghaus’ (1913) forgetting curve reminds us that retrieval practice is essential. Also, learners need to consolidate interrelated concepts and skills covered across units or entire courses. In some cases, learners may need to identify the root cause of the academic difficulties they are experiencing, such as struggling with a concept or skill.
Unlike traditional self-assessments that rely on predetermined questions, adaptive practicing systems trace learners’ knowledge levels as they keep changing. This study designed a CAP system for learning autonomy and efficient adaptivity. As an AI-learner shared control model, ZPD-KT effectively embeds learner confidence and learner control in the model design.
The ZPD-KT model tested significantly increased prediction accuracy compared to the stdBKT model through simulation, but it still has great potential for improvement. For example, the mastery ranges specified in the ZPD-KT framework shown in Table 1 and the weights used for question sequencing as shown in Equations 3 and 4 are all based on educators’ experience and therefore are somewhat arbitrary. They could be further optimized by analyzing learners’ practicing data through machine learning technology. This optimization process could be integrated into the system self-learning module.
Although the CAP system is designed with STEM courses in mind, it could be used for any discipline. Since CAP carefully considers the prerequisite relationships among KCs, it has a tremendous advantage when dealing with subjects that have complex learning topics and hierarchical structures. However, the CAP system does not consider the forgetting factor during the practicing process. To address this issue, we plan to embed the spaced practice principle in the future, which could especially benefit learning outcomes at the lower levels of Bloom’s taxonomy.
Additionally, the ZPD-KT model does not require training with massive historical data, so it eliminates the cold start problem and reduces potential biases caused by training data. While initially designed for self-paced online higher education, CAP could be used in many other online learning environments. However, further research and experiments are needed to validate such hypotheses.
Facilitating self-regulated learning skills is critical for success in education. To do this, an AI-learner shared control model (ZPD-KT) for a confidence-based adaptive practicing (CAP) system for self-paced online STEM courses was designed. Through a simulation, the model design was refined and its effectiveness was tested. In practical terms, the comparison shown in Table 2 suggests that ZPD-KT is substantially more effective than the stdBKT model. This improvement could lead to more personalized and efficient experiences for learners when implemented in educational technology systems.
Although designed to facilitate self-regulated learning, adaptive practicing could also reduce instructor workload for academic support in self-paced online learning. By exploring integrating learner confidence and control in the adaptive practicing system, this study can shed light on researching a new way of keeping human learners in the loop of AI-based adaptive learning.
So far, this study has only investigated confidence rating and question skipping in the AI-learner shared control model. Future research could investigate how other side information is included in the model. For example, learners’ affective states (e.g., confusion, engagement, frustration, and distraction) also indicate learning performance and could be considered in the adaptive practicing model design. At this stage, a simulation was conducted to evaluate the effectiveness of the CAP system and the ZPD-KT model. However, an experiment with real-world courses is planned to evaluate how learners react to the interaction design of the CAP, such as how they feel about the options provided for the confidence rating and question skipping.
Beck, J. E., & Gong, Y. (2013). Wheel-spinning: Students who fail to master a skill. In H. C. Lane, K. Yacef, J. Mostow, & P. Pavlik (Eds.), Artificial intelligence in education. AIED2013 (pp. 431-440). Springer. https://doi.org/10.1007/978-3-642-39112-5_44
Bjork, R. A., Dunlosky, J., & Kornell, N. (2013). Self-regulated learning: Beliefs, techniques, and illusions. Annual Review of Psychology, 64, 417-444. https://doi.org/10.1146/annurev-psych-113011-143823
Broadbent, J., & Poon, W. L. (2015). Self-regulated learning strategies and academic achievement in online higher education learning environments: A systematic review. The Internet and Higher Education, 27, 1-13. https://doi.org/10.1016/j.iheduc.2015.04.007
Broadbent, J. (2017). Comparing online and blended learners’ self-regulated learning strategies and academic performance. The Internet and Higher Education, 33, 24-32. https://doi.org/10.1016/j.iheduc.2017.01.004
Brusilovsky, P. (2007). Adaptive navigation support. In P. Brusilovsky, A. Kobsa, & W. Nejdl (Eds.), The adaptive web (pp. 263-290). Springer. https://doi.org/10.1007/978-3-540-72079-9_8
Brusilovsky, P. (2024). AI in education, learner control, and human-AI collaboration. International Journal of Artificial Intelligence in Education, 34, 122-135. https://doi.org/10.1007/s40593-023-00356-z
Clement, B., Roy, D., Oudeyer, P.-Y., & Lopes, M. (2015). Multi-armed bandits for intelligent tutoring systems. Journal of Educational Data Mining, 7(2), 20-48. https://doi.org/10.48550/arXiv.1310.3174
Corbett, A. T., & Anderson, J. R. (1994). Knowledge tracing: Modeling the acquisition of procedural knowledge. User Modeling and User-Adapted Interaction, 4, 253-278. https://doi.org/10.1007/BF01099821
Deci, E. L., Vallerand, R. J., Pelletier, L. G., & Ryan, R. M. (1991). Motivation and education: The self-determination perspective. Educational Psychologist, 26(3-4), 325-346. https://doi.org/10.1080/00461520.1991.9653137
Doignon, J.-P., & Falmagne, J.-C. (1999). Knowledge spaces. Springer-Verlag. https://doi.org/10.1007/978-3-642-58625-5
Doroudi, S., Aleven, V., & Brunskill, E. (2019). Where’s the reward? International Journal of Artificial Intelligence in Education, 29, 568-620. https://doi.org/10.1007/s40593-019-00187-x
Ebbinghaus, H. (1913). Memory: A contribution to experimental psychology. Annals of Neurosciences, 20(4), 155-156. https://www.doi.org/10.5214/ans.0972.7531.200408
Ekstrand, B. (2015). What it takes to keep children in school: A research review. Educational Review, 67(4), 459-482. https://doi.org/10.1080/00131911.2015.1008406
Gardner-Medwin, T., & Curtin, N. (2007, May 29-31). Certainty-based marking (CBM) for reflective learning and proper knowledge assessment. In REAP International Online Conference on Assessment Design for Learner Responsibility (pp. 1-7). REAP. https://www.ucl.ac.uk/lapt/REAP_cbm.pdf
Holstein, K., Aleven, V., & Rummel, N. (2020). A conceptual framework for human–AI hybrid adaptivity in education. In I. Bittencourt, M. Cukurova, K. Muldner, R. Luckin, & E. Millán (Eds.), Artificial intelligence in education. AIED 2020 (pp. 240-254). Springer. https://doi.org/10.1007/978-3-030-52237-7_20
Hsu, H. C. K., Wang, C. V., & Levesque-Bristol, C. (2019). Re-examining the impact of self-determination theory on learning outcomes in the online learning environment. Education and Information Technologies, 24, 2159-2174. https://doi.org/10.1007/s10639-019-09863-w
Jansen, R. S., van Leeuwen, A., Janssen, J., & Kester, L. (2019). Supporting learners’ self-regulated learning in Massive Open Online Courses. Computers & Education, 146, 103771. https://doi.org/10.1016/j.compedu.2019.103771
Lehmann, T., Hähnlein, I., & Ifenthaler, D. (2014). Cognitive, metacognitive and motivational perspectives on preflection in self-regulated online learning. Computers in Human Behavior, 32, 313-323. https://doi.org/10.1016/j.chb.2013.07.051
Luo, Y., Lin, J., & Yang, Y. (2021). Students’ motivation and continued intention with online self-regulated learning: A self-determination theory perspective. Zeitschrift für Erziehungswissenschaft, 24, 1379-1399. https://doi.org/10.1007/s11618-021-01042-3
Manouselis, N., Drachsler, H., Vuorikari, R., Hummel, H., & Koper, R. (2011). Recommender systems in technology-enhanced learning. In F. Ricci, L. Rokach, B. Shapira, & P. Kantor (Eds.), Recommender systems handbook (pp. 387-415). Springer. https://doi.org/10.1007/978-0-387-85820-3_12
Mosqueira-Rey, E., Hernández-Pereira, E., Alonso-Ríos, D., Bobes-Bascarán, J., & Fernández-Leal, A. (2023). Human-in-the-loop machine learning: A state of the art. Artificial Intelligence Review, 56(4), 3005-3054. https://doi.org/10.1007/s10462-022-10246-w
Nkambou, R., Bourdeau, J., & Mizoguchi, R. (Eds.). (2010). Advances in intelligent tutoring systems. Springer. https://doi.org/10.1007/978-3-642-14363-2
Novacek, P. (2013). Confidence-based assessments within an adult learning environment. In G. Demetrios, J. Sampson, M. Spector, D. Ifenthaler, & P. Isaías (Eds.), IADIS International Conference on Cognition and Exploratory Learning in Digital Age (CELDA 2013) (pp. 403-406). International Association for Development of the Information Society. https://eric.ed.gov/?id=ED562245
Nuryadin, A., Lidinillah, D. A. M., Prehanto, A., Maesaroh, S. S., Putri, I. R., & Desmawati, S. A. (2024). Self-regulated learning in STEM education: A bibliometric mapping analysis of research using Scopus database. International Journal of Education in Mathematics, Science and Technology, 12(4), 919-941. https://doi.org/10.46328/ijemst.4015
Papoušek, J., & Pelánek, R. (2017). Should we give learners control over item difficulty? In M. Tkalcic, D. Thakker, P. Germanakos, K. Yacef, C. Paris, & O. Santos (Eds.), UMAP ’17: Adjunct publication of the 25th Conference on User Modeling, Adaptation and Personalization (pp. 299-303). ACM. https://doi.org/10.1145/3099023.3099080
Pelánek, R. (2017). Bayesian knowledge tracing, logistic models, and beyond: An overview of learner modeling techniques. User Modeling and User-Adapted Interaction, 27(3), 313-350. https://doi.org/10.1007/s11257-017-9193-2
Preheim, M., Dorfmeister, J., & Snow, E. (2023). Assessing confidence and certainty of students in an undergraduate linear algebra course. Journal for STEM Education Research, 6, 159-180. https://doi.org/10.1007/s41979-022-00082-6
Rahdari, B., Brusilovsky, P., He, D., Thaker, K. M., Luo, Z., & Lee, Y. J. (2022). HELPeR: An interactive recommender system for ovarian cancer patients and caregivers. In J. Golbeck, F. M. Harper, V. Murdock, M. Ekstrand, B. Shapira, J. Basilico, K. Lundgaard, & E. Oldridge (Eds.), RecSys ’22: Proceedings of the 16th ACM Conference on Recommender Systems (pp. 644-647). https://doi.org/10.1145/3523227.3551471
Remesal, A., Corral, M. J., García-Mínguez, P., Domínguez, J., SanMiguel, I., Macsotay, T., & Suárez, E. (2023). Certainty-based self-assessment: A chance for enhanced learning engagement in higher education. An experience at the University of Barcelona. In D. Guralnick, M. E. Auer, & A. Poce (Eds.), Creative approaches to technology-enhanced learning for the workplace and higher education. TLIC 2023 (pp. 689-700). Springer. https://doi.org/10.1007/978-3-031-41637-8_56
Schunk, D. H., & DiBenedetto, M. K. (2020). Motivation and social cognitive theory. Contemporary Educational Psychology, 60, Article 101832. https://doi.org/10.1016/j.cedpsych.2019.101832
Smrkolj, Š., Bančov, E., & Smrkolj, V. (2022). The reliability and medical students’ appreciation of certainty-based marking. International Journal of Environmental Research and Public Health, 19(3), Article 1706. https://doi.org/10.3390/ijerph19031706
Sorgenfrei, C., & Smolnik, S. (2016). The effectiveness of e-learning systems: A review of the empirical literature on learner control. Decision Sciences Journal of Innovative Education, 14(2), 154-184. https://doi.org/10.1111/dsji.12095
Vainas, O., Bar-Ilan, O., Ben-David, Y., Gilad-Bachrach, R., Lukin, G., Ronen, M., & Sitton, D. (2019). E-Gotsky: Sequencing content using the zone of proximal development. ArXiv. https://doi.org/10.48550/arXiv.1904.12268
Viberg, O., Khalil, M., & Baars, M. (2020). Self-regulated learning and learning analytics in online learning environments: A review of empirical research. In C. Rensing & H. Drachsler (Chairs), LAK ’20: Proceedings of the Tenth International Conference on Learning Analytics & Knowledge (pp. 524-533). ACM. https://doi.org/10.1145/3375462.3375483
Vygotsky, L. S. (1978). Mind in society: The development of higher psychological processes (M. Cole, V. John-Steiner, S. Scribner, & E. Souberman, Eds.). Harvard University Press.
Weber, G., & Brusilovsky, P. (2001). ELM-ART: An adaptive versatile system for Web-based instruction. International Journal of Artificial Intelligence in Education, 12, 351-384. https://telearn.hal.science/hal-00197328v1
Wong, J., Baars, M., Davis, D., Van Der Zee, T., Houben, G. J., & Paas, F. (2019). Supporting self-regulated learning in online learning environments and MOOCs: A systematic review. International Journal of Human–Computer Interaction, 35(4-5), 356-373. https://doi.org/10.1080/10447318.2018.1543084
Yan, H., Lin, F., & Kinshuk. (2021). Including learning analytics in the loop of self-paced online course learning design. International Journal of Artificial Intelligence in Education, 31, 878-895. https://doi.org/10.1007/s40593-020-00225-z
Yan, H., Lin, F., & Kinshuk. (2022). Removing learning barriers in self-paced online STEM education. Canadian Journal of Learning and Technology, 48(4), 1-18. https://doi.org/10.21432/cjlt28264
Zimmerman, B. J. (2020). Attaining self-regulation: A social cognitive perspective. In Handbook of Self-Regulation (3rd ed., pp. 13-39). Elsevier.
Zohaib, M. (2018). Dynamic difficulty adjustment (DDA) in computer games: A review. Advances in Human‐Computer Interaction, 2018, Article 5681652. https://doi.org/10.1155/2018/5681652
Hongxin Yan is a Learning Designer at Athabasca University in Alberta, Canada and a Doctoral Student at the University of Eastern Finland (UEF). His research interests include adaptive and personalized learning, artificial intelligence (AI) in education, learning analytics, and related fields. Email: hongya@student.uef.fi ORCID: 0000-0002-3729-0844
Fuhua Lin is a Professor in the Faculty of Science and Technology at Athabasca University in Alberta, Canada. His research focuses on adaptive learning systems, artificial intelligence in education, and virtual reality applications for training. He has led multiple NSERC/CFI/Alberta Innovates-funded projects to advance personalized learning technologies. Email: oscarl@athabascau.ca
Kinshuk is a full Professor and the Dean of the College of Information at the University of North Texas, USA. His research interests include learning analytics, mobile learning, ubiquitous learning, personalized learning, and adaptivity. Email: kinshuk@ieee.org